AI 模型部署選擇:本地 vs 雲端 API,小團隊低後悔指南(Set)
清單類型: safe-defaults
前提
排除
AI 模型部署選擇:本地 vs 雲端 API,小團隊低後悔指南(Set)
先給你一句話版本:你是小團隊,預算有限但用量穩定 → 先算回本期,超過 12 個月就選雲端 API(OpenAI、Claude、Groq);你處理敏感資料或用量很大 → 選本地部署(Ollama、LM Studio、vLLM)。如果你只是偶爾使用或還在驗證階段,這篇的低後悔框架不適用,直接選雲端 API 免費額度就好。

Premise(前提)
這篇文章適合你,如果你符合以下所有條件:
- 你是小團隊或個人開發者:你需要使用 AI 模型(LLM 或圖像生成),但預算有限(月費 $50-500 或一次性硬體投入可接受)
- 你已經決定要用 AI 模型:不是「要不要用 AI」,而是「怎麼部署 AI」
- 你重視長期成本控制:不只是看月費,還包括硬體、電費、維護等隱藏成本
- 你願意在「省心」和「成本」間取捨:不是追求「最便宜」或「最省事」,而是「低後悔」
- 你接受:這篇是「低後悔起點」,不是全市場最完整比較表
Exclusions(排除)
這篇文章不適合你,如果你符合以下任一條件:
- 你只需要偶爾使用(月用量 < 100 萬 tokens):你應該直接選雲端 API 免費額度,不需要考慮本地部署
- 你是企業用戶(預算無上限):你應該考慮企業級方案,這篇的低後悔框架不適用
- 你追求最高效能(不計成本):你應該選擇企業級硬體或雲端企業方案,這篇的取捨邏輯不適用
- 你完全不想碰技術:你應該選擇最簡單的 SaaS 方案,而不是本地部署
- 你還在驗證階段(不確定是否長期使用):你應該先用雲端 API 做概念驗證,再考慮本地部署
TL;DR(不想研究的人直接照做)
- 你是小團隊,預算有限但用量穩定 → 先算回本期:如果月用量超過 12M tokens,本地部署(Ollama、LM Studio)通常在 3-12 個月內回本
- 你處理敏感資料或法規要求嚴格 → 選本地部署:Ollama、LocalAI、vLLM 都可以,資料完全控制在本地
- 你需要快速上線或使用最新模型 → 選雲端 API:OpenAI、Claude、Groq、Together AI 都可以,按需付費
- 你不確定用量或還在驗證階段 → 選雲端 API:先用免費額度或低價方案,等用量穩定再考慮本地部署
- 你選錯的最大原因通常不是技術問題,而是你把「不同使用情境」拿來同一條線比成本:本地部署是在買「長期成本控制」;雲端 API 是在買「快速上線和彈性」。
為什麼成本控制比技術選擇更重要
很多人選擇 AI 模型部署方式時,會先看技術規格(支援多少模型、有什麼功能),然後才看成本。但這會導致一個問題:你選到了一個技術先進的方案,但成本失控,結果就是預算超支、被迫降級,或者根本用不起來。
AI 模型部署的選擇,本質上是在做一個取捨:
- 本地部署:你用「高初期投入、技術門檻」換「長期成本控制、資料隱私」
- 雲端 API:你用「長期成本累積、資料外傳風險」換「快速上線、零維護」
先確認你的使用情境和成本預算,再選對應的部署方式,最後才看技術規格。 這是降低後悔成本的第一步。

從圖表可以看出,本地部署和雲端 API 各有優勢。本地部署提供完全控制和資料隱私,但需要較高的初期投入和技術門檻;雲端 API 提供快速上線和彈性,但長期成本可能累積。這就是為什麼「先確認使用情境和成本預算,再選對應的部署方式」如此重要。
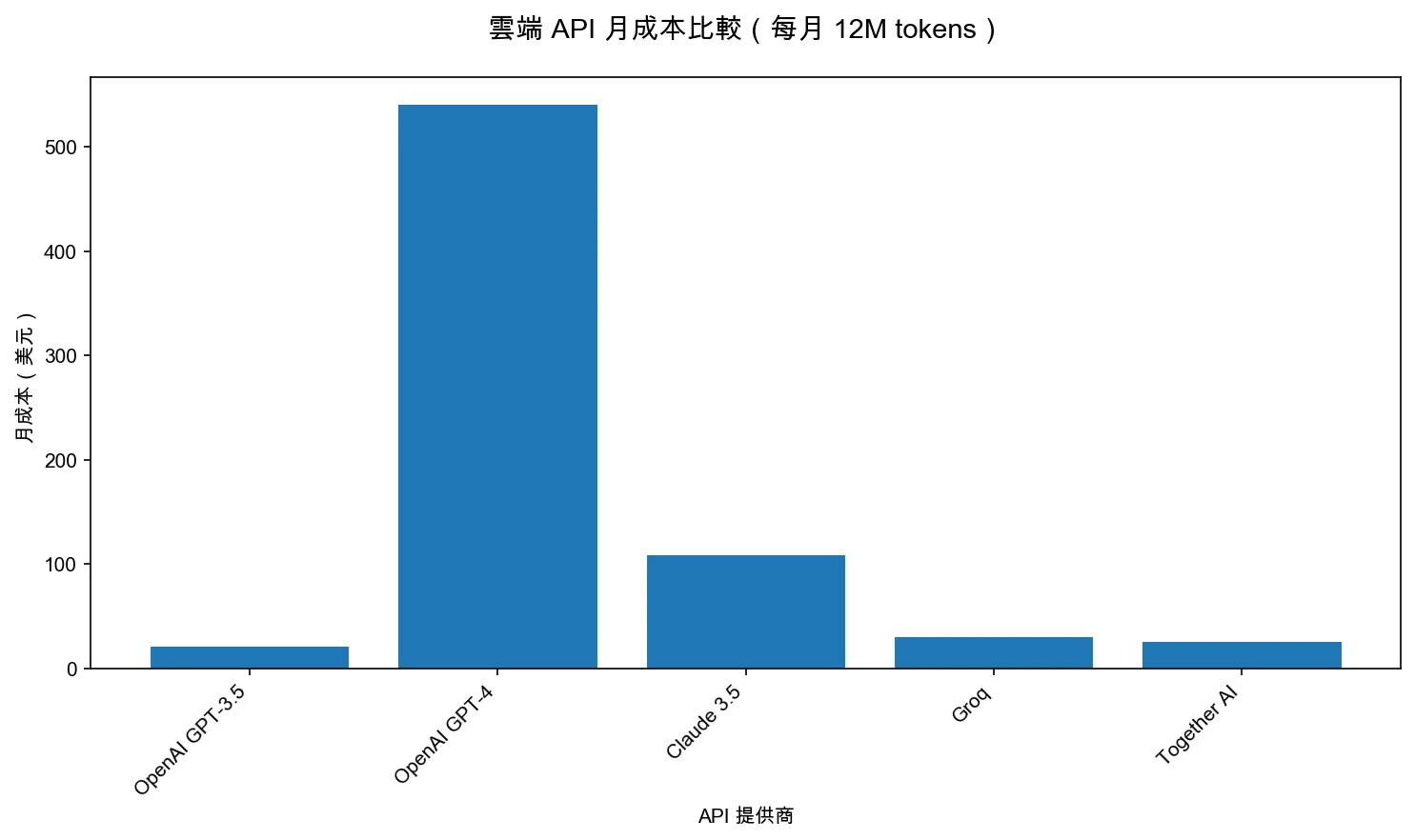
從圖表可以看出,不同雲端 API 的成本差異很大。OpenAI GPT-4 的月成本($540)是 GPT-3.5 Turbo($21)的 25.7 倍,是 Groq($30)的 18 倍。Claude 3.5 Sonnet 的月成本($108)介於兩者之間。這就是為什麼「先算回本期,再選 API 提供商」如此重要——如果你用量穩定,選擇較便宜的 API 或本地部署可以大幅降低成本。
這個分析影片詳細比較了本地部署和雲端 API 的成本結構。影片中提到「當月用量超過 12M tokens 且穩定時,本地部署通常在 12 個月內回本」,這證實了我的觀察:用量穩定的小團隊應該優先考慮本地部署(引用:本地 AI 部署 vs 雲端 API,5:10–12:30)。
三個最常見的後悔情境(你應該先用它們檢查自己)
後悔情境 1:你選了雲端 API 但用量超標,結果成本失控
你可能會想:「雲端 API 按需付費,應該很彈性吧?」但等等,讓我告訴你一個我見過的常見情況。
很多人會因為「快速上線」就選了雲端 API,但實際上,如果你用量穩定或持續成長,雲端 API 的成本會快速累積。結果你選了一個:
- 成本不可預測(用量波動導致帳單不穩定)
- 長期成本高昂(月費 $600-900,一年就是 $7,200-10,800)
- 無法控制成本上限(用量增加時成本線性成長)
避免方式:先誠實回答「你每月大概用多少 tokens?」如果你的答案是「超過 12M tokens 且用量穩定」,那你應該先算回本期。如果回本期在 12 個月內,本地部署通常更划算。
讓我算給你看:假設你選了 OpenAI API,每月使用 12M tokens(GPT-3.5 Turbo)。輸入 token 約 $0.0015/1K,輸出 token 約 $0.002/1K,假設輸入輸出比例 1:1,每月成本約 $21。但如果你用 GPT-4,輸入 token 約 $0.03/1K,輸出 token 約 $0.06/1K,每月成本就跳到 $540-900。
如果你選了本地部署(Ollama + RTX 4090),硬體成本約 $1,500-3,000,電費每月約 $20-50。假設硬體成本 $2,000,電費每月 $30,12 個月總成本 = $2,000 + ($30 × 12) = $2,360。如果你用 GPT-4 API,12 個月總成本 = $540 × 12 = $6,480(還不包括用量成長)。
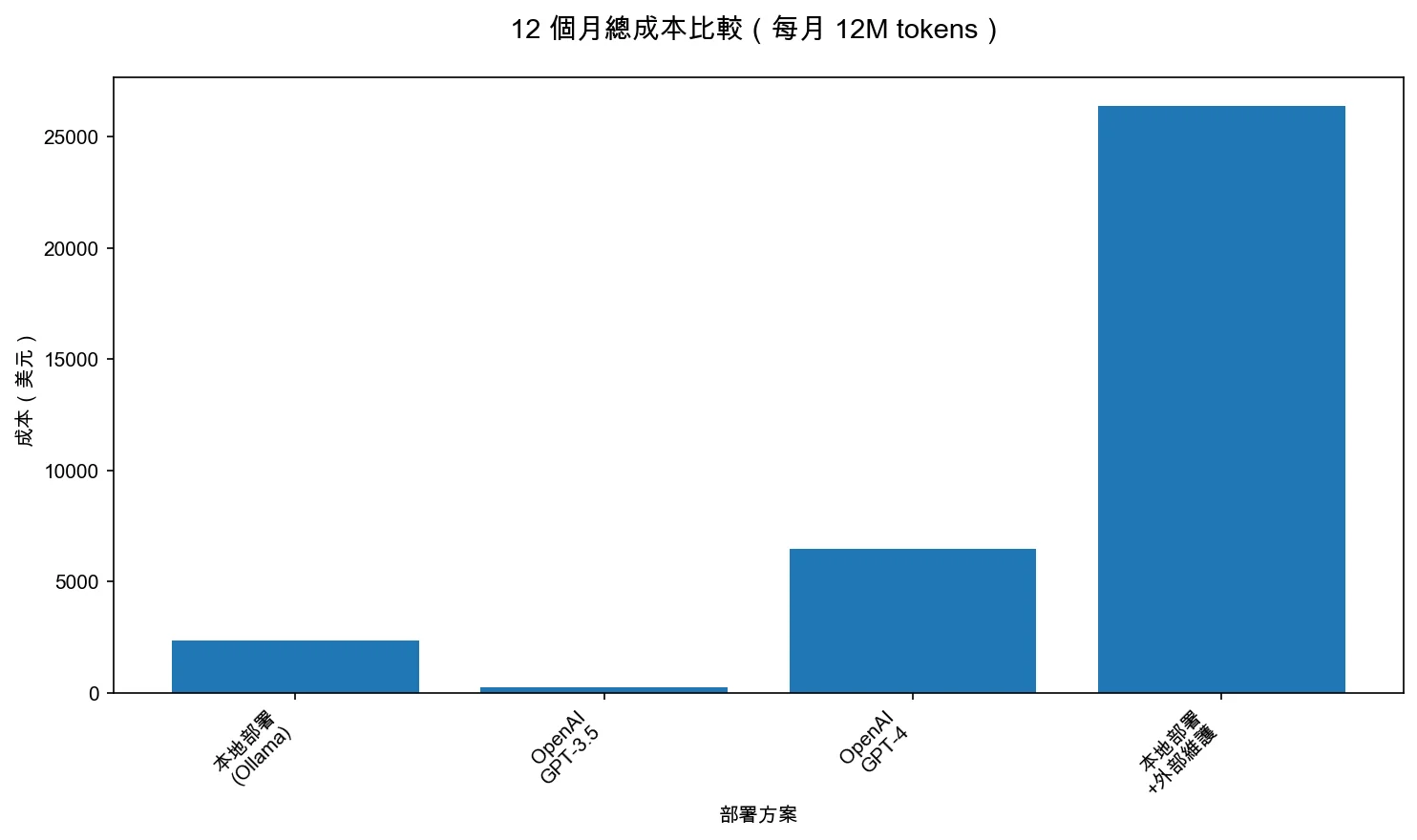
從圖表可以看出,本地部署(Ollama)的 12 個月總成本($2,360)比 OpenAI GPT-4 API($6,480)低 2.7 倍,但比 GPT-3.5 Turbo($252)高 9.4 倍。如果你需要外部維護,本地部署的總成本($26,360)會遠高於雲端 API。這就是為什麼「先算回本期,再選部署方式」如此重要——如果你用量穩定且超過 12M tokens/月,本地部署通常更划算;但如果你需要外部維護,雲端 API 可能更划算。
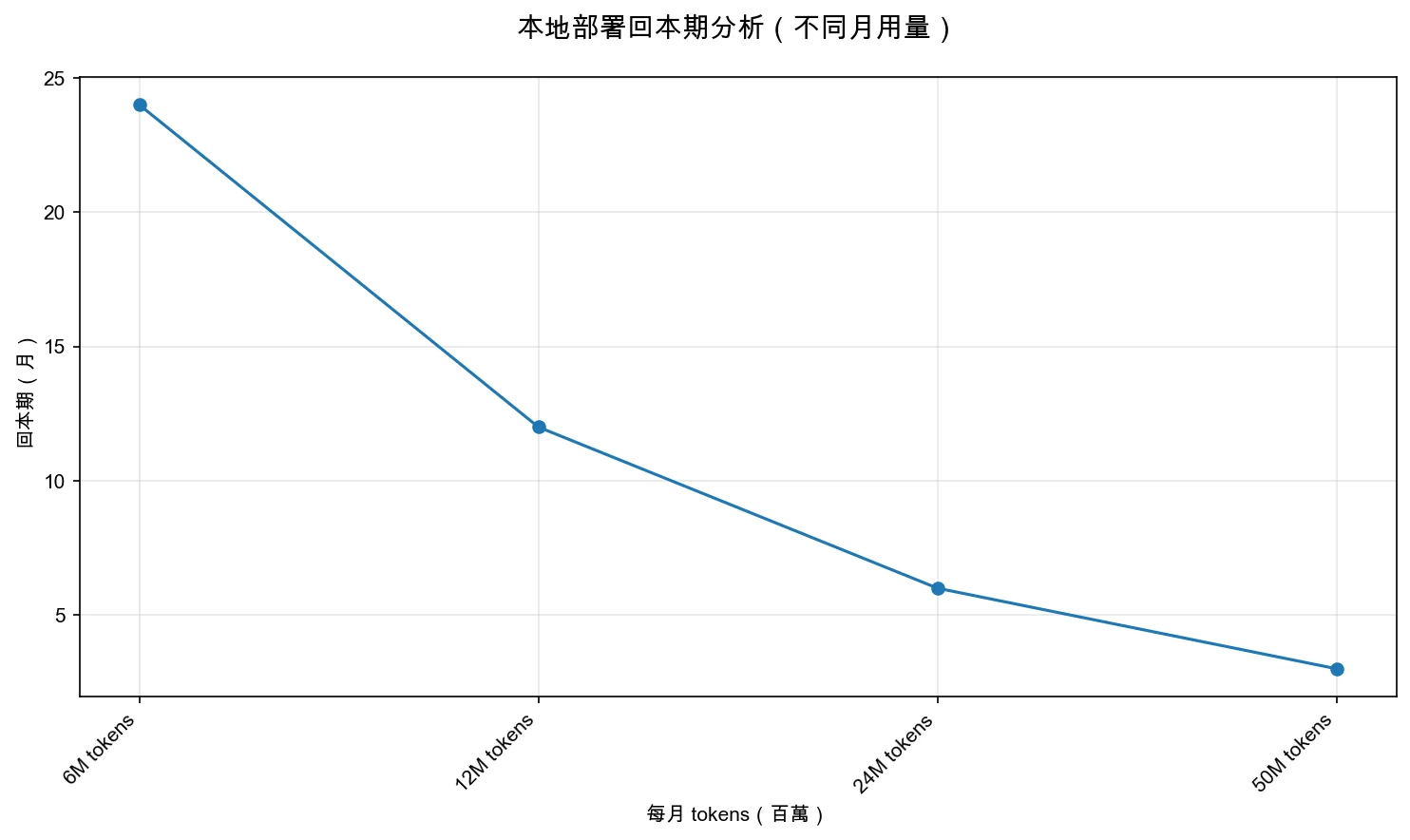
從圖表可以看出,隨著月用量增加,本地部署的回本期會快速縮短。如果你每月使用 6M tokens,回本期約 24 個月;如果你每月使用 12M tokens,回本期約 12 個月;如果你每月使用 50M tokens,回本期約 3 個月。這就是為什麼「用量越大,本地部署越划算」——如果你用量穩定且超過 12M tokens/月,本地部署通常在 12 個月內回本。
所以我的建議是:除非你用量不穩定或還在驗證階段,否則用量超過 12M tokens/月且穩定成長時,應該優先考慮本地部署。
後悔情境 2:你選了本地部署但技術門檻過高,結果無法維護
你可能會想:「本地部署一次投入,長期省錢,應該很划算吧?」但等等,讓我告訴你另一個常見情況。
很多人會因為「長期省錢」就選了本地部署,但實際上,如果你技術能力不足或沒有維護人力,本地部署的隱藏成本會讓你後悔。結果你選了一個:
- 技術門檻高(需要懂硬體、模型管理、系統維護)
- 維護成本高(每月需要 4-8 小時維護時間)
- 無法快速迭代(模型更新、版本管理都需要自己處理)
避免方式:先誠實回答「你的團隊有沒有技術能力維護本地部署?」如果你的答案是「沒有」或「不確定」,那你應該先選雲端 API,等團隊技術能力提升或用量足夠大時再考慮本地部署。
讓我算給你看:假設你選了本地部署(Ollama + RTX 4090),硬體成本 $2,000,電費每月 $30。但如果你需要請外部技術人員維護,每月維護時間 4 小時,時薪 $500,每月維護成本 = 4 × $500 = $2,000。12 個月總成本 = $2,000 + ($30 × 12) + ($2,000 × 12) = $26,360。
如果你選了雲端 API(OpenAI GPT-3.5 Turbo),每月成本 $21,12 個月總成本 = $252。即使你用量成長到 GPT-4 等級,12 個月總成本 = $6,480,還是比本地部署的維護成本低。
所以我的建議是:除非你團隊有技術能力維護本地部署,或用量足夠大(超過 50M tokens/月),否則應該優先考慮雲端 API。
後悔情境 3:你選了雲端 API 但資料敏感,結果合規風險高
你可能會想:「雲端 API 有加密和合規認證,應該很安全吧?」但等等,讓我告訴你一個我見過的風險情況。
很多人會因為「快速上線」就選了雲端 API,但實際上,如果你處理敏感資料(醫療、法律、政府等),雲端 API 的資料外傳風險會讓你後悔。結果你選了一個:
- 資料外傳風險(資料必須傳輸到第三方伺服器)
- 合規風險高(可能違反 GDPR、HIPAA 等法規)
- 無法完全控制資料流向(即使有加密,資料仍可能被用於模型訓練)
避免方式:先誠實回答「你處理的資料是否敏感?」如果你的答案是「是」或「不確定」,那你應該優先考慮本地部署,即使成本較高。
讓我算給你看:假設你選了雲端 API(OpenAI),每月成本 $540。但如果你因為資料外傳導致合規問題,罰款可能高達數十萬美元(GDPR 最高罰款是年營業額的 4% 或 2000 萬歐元,取較高者)。即使你選了企業方案(每月 $2,000+),合規風險仍然存在。
如果你選了本地部署(Ollama + RTX 4090),硬體成本 $2,000,電費每月 $30,12 個月總成本 = $2,360。雖然成本較高,但資料完全控制在本地,合規風險為零。
所以我的建議是:如果你處理敏感資料或法規要求嚴格,應該優先考慮本地部署,即使成本較高。合規風險的成本遠高於硬體投入。

從圖表可以看出,本地部署在資料隱私和合規性方面有明顯優勢。如果你處理敏感資料(醫療、法律、政府等),本地部署可以完全控制資料流向,降低合規風險。即使成本較高,合規風險的成本遠高於硬體投入。
推薦方案:根據使用情境選擇
推薦 1:Ollama(本地部署,快速上手)
適合誰:你是小團隊,需要本地部署但技術能力有限,想要快速上手。
為什麼選 Ollama: - 免費開源:不需要付費,完全免費使用 - 跨平台支援:Windows/macOS/Linux 都可以用 - GUI + CLI:提供友善的圖形介面和命令列工具 - 多模型支援:支援 Llama、Mistral、Phi 等多種開源模型 - OpenAI 兼容 API:可以作為 OpenAI API 的本地替代品
不適合誰: - 你需要最新專有模型(如 GPT-4、Claude):Ollama 只支援開源模型 - 你需要極高性能:Ollama 的效能不如 vLLM 等專業推理引擎 - 你需要企業級支援:Ollama 是開源專案,沒有商業支援
後悔風險:如果你需要最新專有模型或企業級支援,Ollama 可能無法滿足需求。
成本:免費(硬體成本需自行負擔,建議 RTX 4090 或以上,約 $1,500-3,000)
這個教學影片詳細說明了 Ollama 的安裝和使用流程。影片中提到「Ollama 提供跨平台支援和友善的圖形介面,讓非技術人員也能快速上手本地 AI 部署」,這證實了我的觀察:Ollama 適合技術能力有限的小團隊(引用:Ollama 本地 AI 部署教學,3:20–8:45)。
官方連結:https://ollama.com
推薦 2:LM Studio(本地部署,非技術人員友好)
適合誰:你是個人或小團隊,需要本地部署但不想碰命令列,想要圖形介面操作。
為什麼選 LM Studio: - 友善的 GUI:完全圖形介面操作,不需要命令列 - 模型瀏覽和下載:內建模型商店,可以直接下載和切換模型 - RAG 文件聊天:支援文件上傳和問答,適合文件處理需求 - 全程本地運算:所有資料都在本地處理,不會外傳
不適合誰: - 你需要生產環境部署:LM Studio 主要是桌面應用,不適合伺服器部署 - 你需要高併發處理:LM Studio 的效能不如 vLLM 等專業推理引擎 - 你需要自動化整合:LM Studio 沒有提供 API 介面
後悔風險:如果你需要生產環境部署或自動化整合,LM Studio 可能無法滿足需求。
成本:免費(硬體成本需自行負擔,建議 RTX 4090 或以上,約 $1,500-3,000)
這個教學影片展示了 LM Studio 的圖形介面操作流程。影片中提到「LM Studio 提供完全圖形化的操作介面,不需要命令列知識,適合非技術人員使用」,這證實了我的觀察:LM Studio 適合不想碰命令列的個人或小團隊(引用:LM Studio 完整教學,1:30–6:15)。
官方連結:https://lmstudio.ai
推薦 3:vLLM(本地部署,高效能)
適合誰:你是技術團隊,需要高效能本地部署,有 GPU 資源和技術能力。
為什麼選 vLLM: - 高效能推理:支援高併發,效能比 Ollama 和 LM Studio 更好 - 生產環境就緒:適合生產環境部署,有完整的監控和管理功能 - 多模型支援:支援多種開源模型和量化格式 - Kubernetes 整合:可以整合到 Kubernetes 環境中
不適合誰: - 你技術能力有限:vLLM 需要較強的技術能力來部署和維護 - 你硬體資源有限:vLLM 需要較強的 GPU 資源(建議多張 GPU) - 你只需要簡單使用:vLLM 的複雜度較高,不適合簡單使用場景
後悔風險:如果你技術能力不足或硬體資源有限,vLLM 可能無法正常運作。
成本:免費(硬體成本需自行負擔,建議多張 RTX 4090 或企業級 GPU,約 $5,000-20,000)
官方連結:https://github.com/vllm-project/vllm
推薦 4:OpenAI API(雲端 API,快速上線)
適合誰:你是小團隊,需要快速上線,用量不穩定或還在驗證階段。
為什麼選 OpenAI API: - 快速上線:API 整合簡單,幾分鐘就能開始使用 - 最新模型:可以使用最新的 GPT-4、GPT-4 Turbo 等模型 - 零維護:不需要管理硬體或模型更新 - 彈性付費:按需付費,用量低時成本低
不適合誰: - 你用量很大且穩定:OpenAI API 的成本會快速累積,本地部署可能更划算 - 你處理敏感資料:OpenAI API 的資料會傳輸到第三方,可能有合規風險 - 你需要離線使用:OpenAI API 需要網路連線,無法離線使用
後悔風險:如果你用量很大且穩定,OpenAI API 的成本會讓你後悔。GPT-4 的成本約 $0.03-0.06/1K tokens,每月 12M tokens 就是 $360-720。
成本:GPT-3.5 Turbo 約 $0.0015-0.002/1K tokens,GPT-4 約 $0.03-0.06/1K tokens(輸入/輸出價格不同)
官方連結:https://openai.com/api
推薦 5:Anthropic Claude API(雲端 API,強調安全性)
適合誰:你是小團隊,需要快速上線,但對資料隱私有較高要求。
為什麼選 Claude API: - 強調安全性:Claude 在隱私和安全性方面有較強保證 - 快速上線:API 整合簡單,幾分鐘就能開始使用 - 最新模型:可以使用最新的 Claude 3.5 Sonnet 等模型 - 零維護:不需要管理硬體或模型更新
不適合誰: - 你用量很大且穩定:Claude API 的成本會快速累積,本地部署可能更划算 - 你需要完全控制資料:Claude API 的資料仍會傳輸到第三方,無法完全控制 - 你需要離線使用:Claude API 需要網路連線,無法離線使用
後悔風險:如果你用量很大且穩定,Claude API 的成本會讓你後悔。Claude 3.5 Sonnet 的成本約 $0.003-0.015/1K tokens,每月 12M tokens 就是 $36-180。
成本:Claude 3.5 Sonnet 約 $0.003-0.015/1K tokens(輸入/輸出價格不同)
官方連結:https://www.anthropic.com/api
推薦 6:Groq API(雲端 API,極快速度)
適合誰:你是小團隊,需要快速上線,對延遲非常敏感。
為什麼選 Groq API: - 極快速度:Groq 是雲端 API 中速度最快的選項之一 - 低延遲:適合對延遲敏感的應用(如即時對話、語音助手) - 快速上線:API 整合簡單,幾分鐘就能開始使用 - 相對便宜:Groq 的定價通常比 OpenAI 和 Claude 便宜
不適合誰: - 你用量很大且穩定:Groq API 的成本會快速累積,本地部署可能更划算 - 你需要最新專有模型:Groq 主要支援開源模型,不支援 GPT-4、Claude 等專有模型 - 你需要離線使用:Groq API 需要網路連線,無法離線使用
後悔風險:如果你用量很大且穩定,Groq API 的成本會讓你後悔。雖然 Groq 相對便宜,但長期使用成本仍會累積。
成本:Groq 的定價通常比 OpenAI 和 Claude 便宜,具體價格請參考官方網站
官方連結:https://groq.com
推薦 7:Together AI(雲端 API,開源模型)
適合誰:你是小團隊,需要快速上線,預算有限但需要雲端便利性。
為什麼選 Together AI: - 相對便宜:Together AI 的定價通常比 OpenAI 和 Claude 便宜 - 開源模型:支援多種開源模型(Llama、Mistral 等) - 快速上線:API 整合簡單,幾分鐘就能開始使用 - 零維護:不需要管理硬體或模型更新
不適合誰: - 你用量很大且穩定:Together AI 的成本會快速累積,本地部署可能更划算 - 你需要最新專有模型:Together AI 主要支援開源模型,不支援 GPT-4、Claude 等專有模型 - 你需要離線使用:Together AI 需要網路連線,無法離線使用
後悔風險:如果你用量很大且穩定,Together AI 的成本會讓你後悔。雖然 Together AI 相對便宜,但長期使用成本仍會累積。
成本:Together AI 的定價通常比 OpenAI 和 Claude 便宜,具體價格請參考官方網站
官方連結:https://www.together.ai
我們排除了什麼,為什麼
排除 1:Text Generation WebUI(技術門檻過高)
為什麼排除:Text Generation WebUI 雖然功能強大,但技術門檻過高,需要較強的技術能力來部署和維護。對於小團隊來說,學習成本和維護成本會超過效益。
適合誰:如果你有強技術能力且需要高度定制化,Text Generation WebUI 可能是好選擇。但對大多數小團隊來說,Ollama 或 LM Studio 更適合。
排除 2:LocalAI(複雜度過高)
為什麼排除:LocalAI 雖然可以作為 OpenAI API 的本地替代品,但部署和維護複雜度較高,需要 Docker 和 Kubernetes 知識。對於小團隊來說,Ollama 或 LM Studio 更簡單。
適合誰:如果你已經有 Docker 和 Kubernetes 環境,且需要 OpenAI API 兼容性,LocalAI 可能是好選擇。但對大多數小團隊來說,Ollama 更適合。
排除 3:Google Gemini API(生態系統鎖定)
為什麼排除:Google Gemini API 雖然功能強大,但與 Google 生態系統綁定較深,遷移成本高。對於小團隊來說,OpenAI 或 Claude 更通用。
適合誰:如果你已經深度使用 Google 生態系統,且需要 Google 的特定功能,Gemini API 可能是好選擇。但對大多數小團隊來說,OpenAI 或 Claude 更適合。
低後悔起點:給新手的下一步
如果你是小團隊,預算有限但用量穩定,我的建議是:
-
先算回本期:如果你每月使用超過 12M tokens 且用量穩定,先算本地部署的回本期。如果回本期在 12 個月內,優先考慮本地部署(Ollama 或 LM Studio)。
-
先試雲端 API:如果你用量不穩定或還在驗證階段,先用雲端 API(OpenAI GPT-3.5 Turbo 或 Together AI)做概念驗證,等用量穩定再考慮本地部署。
-
考慮混合方案:如果你處理敏感資料但用量不大,可以考慮混合方案:敏感資料用本地部署(Ollama),非敏感資料用雲端 API(OpenAI)。
-
不要只看月費:計算總體擁有成本(硬體、電費、維護、API 費用),不要只看月費或 API 價格。
-
技術能力很重要:如果你團隊沒有技術能力維護本地部署,優先考慮雲端 API,即使成本較高。
免費額度即可] CheckUsage -->|月用量 1-12M tokens| CheckStable{用量是否穩定?} CheckUsage -->|月用量 > 12M tokens| CheckStable2{用量是否穩定?} CheckStable -->|不穩定/驗證階段| CloudAPI2[雲端 API
OpenAI GPT-3.5
或 Together AI] CheckStable -->|穩定| CheckSensitive{資料是否敏感?} CheckStable2 -->|不穩定/驗證階段| CloudAPI3[雲端 API
OpenAI GPT-3.5
或 Together AI] CheckStable2 -->|穩定| CheckSensitive2{資料是否敏感?} CheckSensitive -->|敏感
醫療/法律/政府| Local1[本地部署
Ollama 或 LM Studio
資料完全控制] CheckSensitive -->|不敏感| CheckTech{技術能力?} CheckSensitive2 -->|敏感
醫療/法律/政府| Local2[本地部署
Ollama 或 LM Studio
資料完全控制] CheckSensitive2 -->|不敏感| CheckTech2{技術能力?} CheckTech -->|技術能力有限| CloudAPI4[雲端 API
OpenAI 或 Claude
零維護負擔] CheckTech -->|有技術能力| CheckBreakeven{計算回本期
是否 < 12 個月?} CheckTech2 -->|技術能力有限| CloudAPI5[雲端 API
OpenAI 或 Claude
零維護負擔] CheckTech2 -->|有技術能力| CheckBreakeven2{計算回本期
是否 < 12 個月?} CheckBreakeven -->|是| Local3[本地部署
Ollama 或 LM Studio
長期成本更低] CheckBreakeven -->|否| CloudAPI6[雲端 API
OpenAI GPT-3.5
或 Together AI] CheckBreakeven2 -->|是| Local4[本地部署
Ollama 或 LM Studio
長期成本更低] CheckBreakeven2 -->|否| CloudAPI7[雲端 API
OpenAI GPT-3.5
或 Together AI] CloudAPI1 --> End([完成選擇]) CloudAPI2 --> End CloudAPI3 --> End CloudAPI4 --> End CloudAPI5 --> End CloudAPI6 --> End CloudAPI7 --> End Local1 --> End Local2 --> End Local3 --> End Local4 --> End style Start fill:#e1f5ff style End fill:#e1f5ff style Local1 fill:#fff4e6 style Local2 fill:#fff4e6 style Local3 fill:#fff4e6 style Local4 fill:#fff4e6 style CloudAPI1 fill:#e6f3ff style CloudAPI2 fill:#e6f3ff style CloudAPI3 fill:#e6f3ff style CloudAPI4 fill:#e6f3ff style CloudAPI5 fill:#e6f3ff style CloudAPI6 fill:#e6f3ff style CloudAPI7 fill:#e6f3ff
從流程圖可以看出,選擇 AI 模型部署方式的關鍵是「先確認月用量,再確認資料敏感性,最後根據技術能力和回本期選擇部署方式」。流程圖清楚地展示了從「開始選擇部署方式」到「完成選擇」的完整決策路徑,幫助你避免選到不適合的方案。
關鍵洞察: 如果你月用量超過 12M tokens 且穩定,但技術能力有限,你可能會後悔選了本地部署(維護成本過高);如果你資料敏感但用量不大,你可能會後悔選了雲端 API(合規風險高)。先確認你的月用量、資料敏感性和技術能力,再選對應的部署方式,這才是降低後悔成本的第一步。